What is conversational programming?
It’s not widely talked about yet, but it will be.
To understand why, I’m going to build on my previous HackerNoon post on “Why the fuss about serverless”. That post discussed the historical rise of DevOps associated with changing characteristics of compute (the shift from high to low MTTR), the rise of serverless and the development of an emerging practice built upon serverless. I called that practice FinDev in 2016. In the end we finally got a moniker of FinOps (2018) and subsequently a foundation, a book (O’Reilly Cloud FinOps) and several conferences built around those concepts of visibility into financial value and gluing together component services. This is all good but it’s not the end of the story.
One of the questions that I was asked back in 2016 was “What comes after serverless”? I responded “Conversational programming”. It’s about time that I make clear what I mean and what its impact is going to be. At the same time, it’s probably worth discussing platform engineering which is a mix of helpful and harmful practices. However, before we can get started, you’ll need some background information.
BACKGROUND
For this post, I’m going to assume that you have a passing familiarity with mapping, you have read the previous post on serverless and concepts like co-evolution are not alien to you. I’m also going to use the current popular terms like composable architecture (old skool was componentisation, they are the same thing) which are all derived from the ideas of compositionality — the ability to break down into and build with components. Just in case, I’ll re-emphasise that :-
1) co-evolution refers to the change of practice with the underlying evolution of the technology due to its changing characteristics. For example, as compute evolved from product to a utility (nee cloud) then the change of characteristic from high to low MTTR (mean time to recovery) enabled a new set of practices to form which later became known as DevOps.
2) Red Queen refers to how we have no choice over evolution. As a technology evolves to more of a utility, we gain operational efficiency plus speed (due to the co-evolved practices) plus new sources of value as the combination of efficiency and speed allows us to create new things which we previously only dreamed of. These “new” things exist in the adjacent unexplored, the space of options that was previously too costly for us but evolution of technology has now enabled. As a competitor adapts they gain efficiency, speed and value which creates pressure on all others to adapt. This pressure mounts as more competitors adapt until all are eventually forced to change. It’s why guns replaced spears or electric lamps replaced gas lamps.
3) Inertia refers to our reluctance to adapt to this new world. There are 16 different forms of inertia including pre-existing capital, pre-existing business model, loss of political capital and so forth. In general terms, it’s our past success with an existing model of technology that creates inertia to adapting to the new world.
With these basics in place, let us draw a map of the existing landscape.
THE MAP
Let us start with a basic map of technology, see figure 1.
Figure 1 — A basic map of technology

In the map above, a user has some need which is normally met by an application running on a device. The application is coded in some form of IDE which is built upon some concept of coding practice. That coding practice requires a run-time (e.g. LAMP or .Net) which has composable elements (e.g. libraries) which in turn run in some form of container (whether a virtual container or operating system). These containers run on some form of compute provided through a concept of architectural practice (e.g. enterprise class machines with N+1 redundancy).
A number of components are shown as squares. These represent a pipeline of choice e.g. for applications we might have a choice from novel apps to common place apps. Pipelines are used in maps when we have mutliple things with a common meaning e.g. “power” can mean renewable or fossil fuel or nuclear — they are all sources of “power”. Each of the choices that we can make are often independently evolving things e.g. nuclear doesn’t evolve to renewable but instead they evolve independently. They are not always independent though and we can use a pipeline to represent a choice in the evolution of a thing. For example, a novel map may evolve to a common place app.
To explain this more clearly, let us expand out the map to discuss the serverless space.
Figure 2 — The Serverless Map.

In the map above, I’ve expanded out a number of the pipelines. For example, in compute we had the choice to use servers or cloud circa 2006 and onwards. For architectural practice we had developed best practice for use of servers (capacity planning, scale up, N+1, disaster recovery test) and we developed emerging architectural practices for cloud (aka compute as a utility). That practice has evolved, it was given a name DevOps and is currently good practice (i.e. there is a convergence in terms of what DevOps means).
To be clear, good practice for compute as a utility is called DevOps whilst “best” practice for compute as a product (aka servers) is these days called Legacy.
Equally, from 2014, the run-time has the option of LAMP / .Net or serverless environment such as Lambda or Azure. The coding practice itself has changed (the subject of the earlier post) with greater use of financial metrics and component services with the code acting more as a glue.
Now, all of these components are evolving, so let us bring it upto date by marking on the evolution and actually date the map. Given we’re already discussing discrete components in the pipelines, we can simply remove the surrounding pipelines. This gives us figure 3.
Figure 3 — Serverless Map, 2023.

From the map, servers shifted to cloud and enabled a practice called DevOps which is rapidly evolving heading towards best architectural practice for cloud. The legacy practice is actually best architectural practice for compute as a product (i.e. servers) but we call it legacy because it’s on the way out. Common libraries are evolving to more component services in the FinOps world of serverless whereas best coding practice for use of LAMP/ .Net is built upon the concept of common libraries. It too is destined for a moniker of legacy. The LAMP / .Net world is tightly linked to underlying orchestration tools and containers whereas in the serverless world the underlying architecture is abstracted away. In other words, in the serverless world you don’t care about underlying infrastructure.
Of course, there will always be exceptions such as being a major scale provider of a component i.e. AWS worries about racks and physical servers because it provides EC2. It worries about infrastructure because it provides Lambda. However, most of us do not operate at this hyperscale and resistance to using such services is not normally based upon positive ideas of a better service but fear i.e. fear of lock-in, fear of loss of control. In other words, it’s normally inertia to change or in some cases a percieved regulatory barrier to adoption. I say perceived because in almost every single instance where I’ve been told “the regulators won’t allow us” — the regulators weren’t actually the problem.
This is not to say that lock-in is not a concern but our lack of understanding of physical and digital supply chains including how evolved the components are, the excludability of components, their substitutability and rivalrousness means that we have little to no visibility of the risk in our supply chains. Even the US executive order for SBOMs is only a starting point on a very long journey. The blunt truth is that Microsoft, Google and AWS will almost certainly have a far better understanding (as exhibited by their ability to provide some embedded carbon information) of their supply chains along with greater resilience than your home grown operation. In a global shortage for silicon chips, these hyperscalers are more likely to secure supplies than your “mom and pop” investment bank operation serving a few million customers or your “corner shop” University with a few tens of thousands of students. Anyone in purchasing will tell you tales of how difficult it has been to get hold of computers and peripherals.
WHAT IS CONVERSATIONAL PROGRAMMING?
When you think about the act of writing an application today, it is often an act of gluing together a few discrete component services with some code in a utility run-time environment such as Lambda. Well … at least, it should be. There are an awful lot of organisation dealing with much lower order components such as racking machines or worrying about container orchestration than there needs to be. That’s normal, the Red Queen effect doesn’t mean everyone changes at the same time. It’s a non linear shift (often called a punctuated equilibrium) and companies will get there eventually. However, if you want to read about what good looks like then I’d suggest “The Value Flywheel Effect”.
Even in this serverless world, the act of programming still requires you to think about what component services need to be glued together. That means you have to break down the problem into components, find component services that match, determine what is missing and hence what you will need to build, then build it and glue it all together. That is still a lot of work to be done and to be blunt, it’s work that can mostly be automated and achieved through some form of intelligent compiler. This leads us to conversational programming.
Let us think about our IDE (integrated development environment). Today, they are very human centric i.e. built upon an expectation that humans will write the code. In a conversational programming world you tell the system what you want, or least provide it prompts for that. The IDE will be more built around the concept of Human + AI rather than just human. Let us map that out in figure 4.
Figure 4 — Conversational Programming, 2023
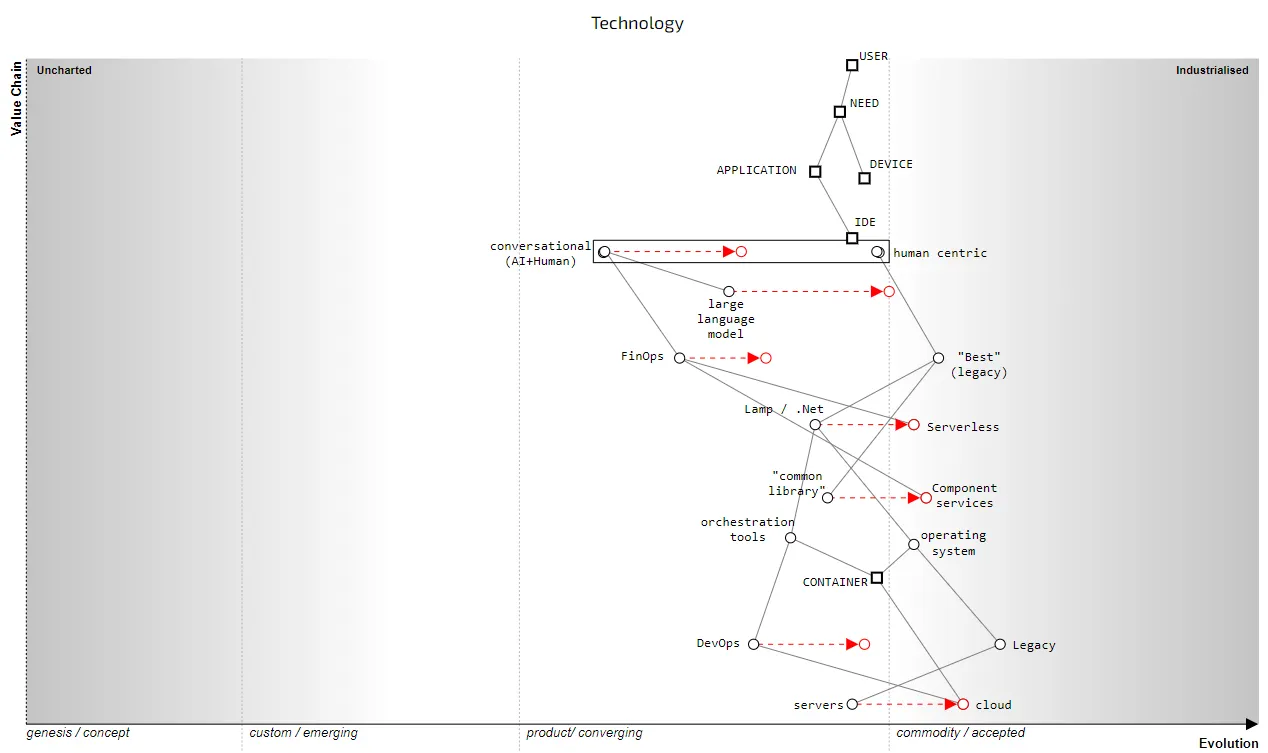
The rapid evolution of large language models towards more of a commodity service will enable more conversational styles of programming. If you think this is science fiction then an example of this was provided at AWS RE:Invent in 2019 by Aleksandar Simovic. This doesn’t mean that the system will build everything for you, there will always be edges that need to be crafted but the majority of what is built today is repetition of code that has already been done.
I want to emphasise the point above by thinking about an application, in fact any application. If you take an application and start with the user needs and then map out the components required then you will find that the majority of the components have been built somewhere else. As a rule of thumb, around 95% of the code we need to build has already been written. Unfortunately, we often don’t have an effective way of finding that code that represents the same function as the code you were about to write. This is why IT shops endlessly build the same things over and over again.
Systems like ChatGPT are stochastic parrots i.e. they are great at producing content based upon “statistical” analysis of huge volumes of similar content (we will come back to the “statistical” later). Hence, today you can prompt ChatGPT to draw a circle in python and it will deliver :-
import turtle
# Create a turtle object
t = turtle.Turtle()
# Draw a circle with radius 100 pixels
t.circle(100)
# Keep the window open until it is closed manually
turtle.done()But helping you write code is not enough. What any conversational system should be doing is watching as you write code and interrupting with a polite “excuse me, you don’t need to build that … just use this”.
The question you should be asking is whether the system can build or suggest things that it has never seen or been exposed to before?
“Perhaps”, but more on that later.
If you prompt ChatGPT to write the control system for a sendor in a future teleportation system … it’ll write something like :-
from qiskit import QuantumCircuit, Aer, execute
# Initialize a quantum circuit with 2 qubits and 2 classical bits
qc = QuantumCircuit(2, 2)
# Create an entangled pair of qubits
qc.h(0)
qc.cx(0, 1)
# Measure the qubits and store the results in the classical bits
qc.measure([0, 1], [0, 1])
# Simulate the circuit using the local qasm simulator
simulator = Aer.get_backend('qasm_simulator')
result = execute(qc, simulator, shots=1).result()
# Get the measurement results as a string
measurement = result.get_counts(qc)
# Print the measurement results
print(measurement)With an awful lot of caveats about how it’ll need “modification, integration with other components, the code only demonstrates how to create an entangled pair of qubits in a local simulation but in a real teleportation system then the quantum channel would likely be implemented using specialized hardware and creating a complete teleportation system would require significant modifications and additional components beyond the simple sender’s control system code provided earlier”.
In other words, it doesn’t know or more importantly it lacks the data to provide a statistically accurate enough result. To do so will require discovery which is why the human + AI element will be so important. If it could write the entire system on its own then that would mean the system has been written so many times before that you shouldn’t be writing it.
At this point we get to the “perhaps” and “statistical” bits. Our stochastic parrot isn’t some some sort of linear analysis of text but a model trained on text. Yes, it is providing what it considers to be the statistically right answer to any question but there can be lots of hidden things in the data that it is trained upon including things that no human has noticed before. An example of this can be found in an AI that can determine race from X-Ray images. This, in itself, creates all sorts of problems but it also begs a question. What if there are hidden meta strategies for innovation in the training data set that an AI can learn? Perhaps it could learn those?
As time passes, we may find that these large language models are more effective stochastic parrots than ourselves or that we’re not stochastic parrots at all. Every generation from the machine age through the age of electricity to the computer telecommunications revolution has described the human mind through the wonders of that age — the mind is a clockwork machine, an electromechanical device, a computer. They were all wrong.
When we do finally get around to building some future sender controller for a teleportation system, you can bet that 95% of the code will have been written beforehand. Even if these AI systems haven’t learnt those meta strategies and aren’t writing it all, we can at least hope that they will help us avoid rebuilding the wheel. I say hope because in my darkest moments, I suspect some future teleportation engineer will start by coding a login and user registration function. Hands up if you’ve ever written one? … more than one? … more than a dozen? How many decades have people been doing this? You get the point.
PROMPT ENGINEERING
The current state of conversational programming is prompt engineering. The prompt takes the form of a question i.e. how do I draw a circle in python? What would the code for a sender control system written in python look like? Examples of which can be seen using large language models such as ChatGPT.
It’s only a matter of time before OpenAI (ChatGPT) is tightly coupled into Azure’s development environment and programming will start to look more like a conversation between an engineer with an AI (as per Nicholas Negroponte’s vision) making recommendations for changes and addition of services. If you wish to see the future then a wonderful example of conversational programming can be found in the marvellous StarTrek Voyager and the “Delete the wife” scene.
Of course, much of this will start with written systems but it’s a small jump to voice from there. What is relevant is the conversation itself and not the use of the written word or voice. One thing you might note in the map is how I’ve linked FinOps to conversational programming. Serverless has brought remarkable changes such as refactoring having financial value to the focus on financial visibility within code (including carbon cost of code) and these are unlikely to be lost in a conversational programming world. Again, those decisions are ones which an AI can help with. It’s not just the code itself (and reducing duplication) that will matter in these IDEs but the meta data such as the cost per function and capital flow within an application whether carbon or dollar or yuan. However, that’s not the only reason. I hold a view that the discovery, interrogation and integration at the functional level will be a key part of this ( as per the Aleksandar Simovic example). It’s why I’m not willing to bet on ChatGPT yet. I suspect the abstraction layer and fundamental model is slightly off target. We’re more in the “Sun Cloud” phase of conversational programming. However, more on that later … let us see how this plays out a bit before I lay that card on the table.
We’re still waiting for those conversational programming environments to fully form but we’re getting close. The technology is there (i.e. large language models), the concept is there (i.e. conversational programming) and the attitude is there (i.e engineers getting swamped by complexity). All the factors needed are in place, it’s only a question of how quickly this evolves and which actor launches first at the “right” level of abstraction — Microsoft or AWS or Google or Baidu? Of course, whomever does drive this to more of a utility will gain the advantage of the meta data for applications built on top. This is a huge strategic advantage which in the past AWS has thoroughly enjoyed and made use of (see Reaching Cloud Velocity) and it’s at the heart of the ILC model (described in that book). Which is why I can’t see AWS doing an IBM and letting Microsoft walk away with this show. I suspect that in the West, AWS will be ahead on this race again (due to its severless advantage). In any case, it’ll be an interesting battle.
I want you take a moment to think about this. The speed of one company with engineers building systems through conversational programming (i.e. a discussion with the system) versus the speed of a company whose engineers are messing around with containers and orchestration systems (such as kubernetes clusters) versus the speed of a company whose engineers are still wiring servers in racks. I want you to think about the Red Queen effect and realise that you will have no choice over this evolution.
Before you ask whether I have a problem with kubernetes clusters, I should be clear. I have no issue with kubernetes clusters any more than I have an issue with GPUs. My problem is that if you’re a bank you shouldn’t be waking up one day and going “we need to build our own GPU” or “we need to build our own Linux” or “we need to build our own kubernetes cluster”. That’s like a taxi firm announcing it is getting into tire design.
SO WHEN WILL THIS HAPPEN?
Back in 2019, I put together a rough timeline for when this would all start to kick off, see figure 5. I put a stake in the ground around 2020 to 2023 which means sometime this year. However, it’ll take time before it is seen as a future norm and a lot depends upon actors actions which are notoriously difficult to predict. We’ve also had a number of shocks to the economic system which might have delayed things. That said, with systems like GitHub’s CoPilot and even AWS CodeGuru, you could argue we’ve already started this race. I would say we’re not there yet, we’re still in the “Sun Cloud” phase i.e. almost there but not quite.
Figure 5 — Timeline, 2019.
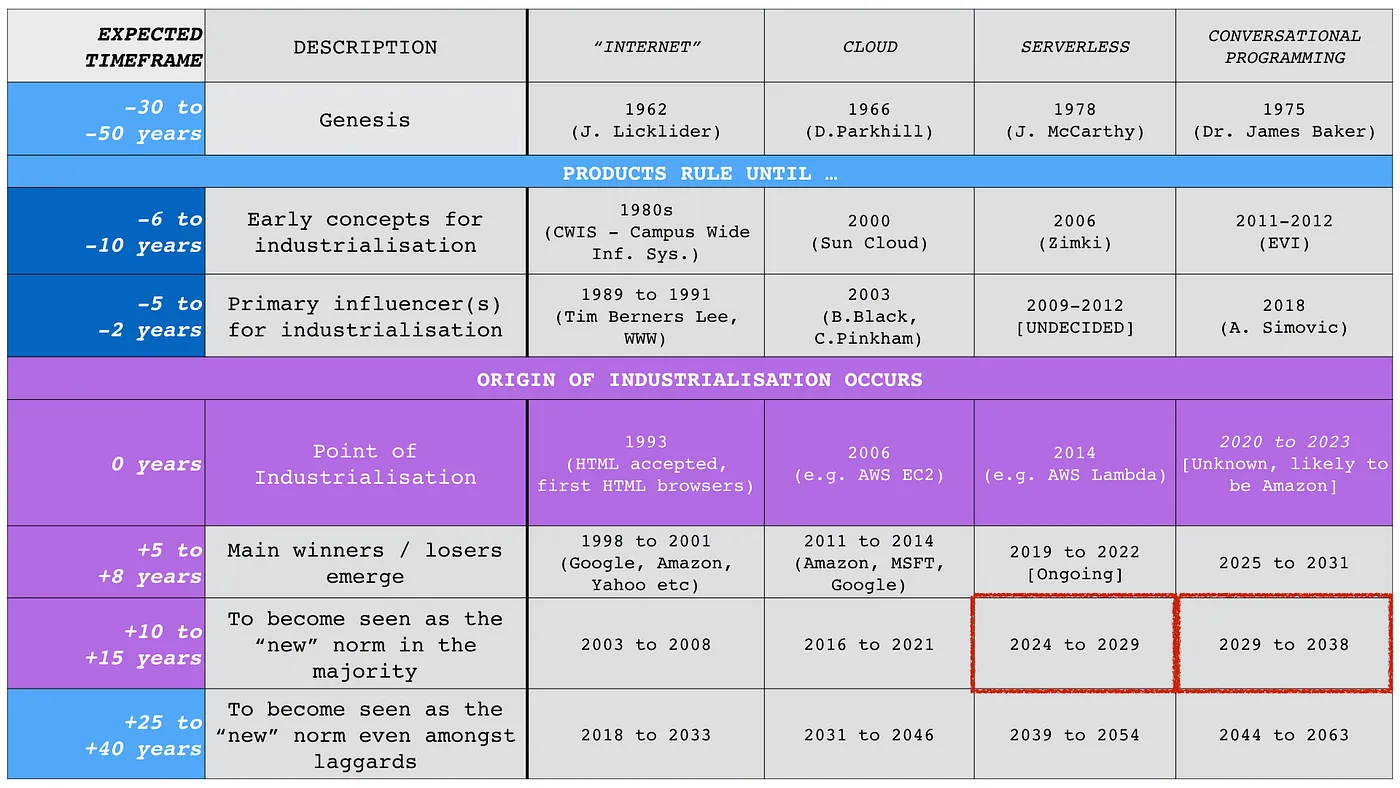
As with all these changes (cloud plus devops, serverless plus finops, conversational programming plus any new moniker for the practice to built on top), there will be the usual gains in efficiency, speed and new sources of value. It will be a punctuated equilibrium (non linear change) which means it will seem to be growing slowly but the doubling rate will catch out most analysts. There will be the usual inertia, the usual crowd of CxOs dismissing it as a fad followed by the usual panic and scramble for skills. There will also be the usual nonsense peddled by large management consultants. It’s probably worth listing these :-
1) You’ll need less engineers. Nope. See Jevon’s paradox. You’ll need to retrain to a new world but you’ll end up doing more stuff. You’ll need those engineers because someone has to do the “thinking”. The system is an assistant to the process, in much the same way as we observe in Centaur Chess. [Please note, general purpose intelligence or “thinking machines” are far away in our future. Stochastic parrots are extremely useful but as far as we are aware they don’t understand the meaning of what they are doing.]
2) It’ll reduce IT budgets. Nope. See Jevon’s paradox again. You’ll end up doing more stuff, more cost efficiently.
3) You have choice. Nope. See Red Queen Effect. This is only a question of “when” not “if”.
4) It’s only for startups. Nope. Startups have less past success and hence lower inertia barriers to change. Large enterprises will resist the change due to the pre-installed capital. Eventually, they will have no choice. See Red Queen Effect.
5) We can build our own. Nope. Well, technically you can but you’ll regret it. Doesn’t mean that won’t stop hordes of self interested vendors trying to persuade you to do so for reasons of “security”, “lock-in” and “customisation to your needs”.
6) I can make a more efficient application by hand crafting the code. Nope. Well, technically you can but the time taken to hand craft it all will be vast (especially if you decide to go down to the level of containers or even worse hardware) compared to the speed at which competitors will move. I’d also suggest reading into Centaur Chess if you think even the most gifted engineer will outcompete an average engineer with an average AI.
7) It’ll be the death of DevOps / FinOps etc. Nope. Well, technically it will be but that takes a very long time. Never underestimate how long legacy (i.e. toxic) IT sticks around. So whilst it’ll take 5–8 years to see who the winners and losers in this conversational programming world are, it’ll take 10–15 years to become seen as the new norm and anywhere from 30 to 45 years for the old world to truly disappear into very small niches.
A NOTE ON PLATFORM ENGINEERING
If I look at the map above (figure 4), then all those components on the right hand side can be discussed as building a platform — a cloud platform of utility infrastructure, a serverless platform, a platform of component services and eventually a conversational programming platform etc. In general, it’s not a good idea to provide components as services exposed through APIs to others unless those components have become industrialised which is why conversational programming requires large language models to become more industrialised.
There are a number of discrete skills — code repository, toolsets, monitoring — around those “platforms” but in general the main platform principles needed are build discrete components, build WITH discrete components and shift as much of the platform to utility providers. Unfortunately, the term platform engineering seems to have got wrapped up with the idea of building your own platform. This is downright harmful if there are utility providers out there. I’ve even listened to people talk about their data centres as a platform. I’m afraid, those companies are going to struggle in a world of conversational programming particularly as the training for some of these large language models can run into the hundreds of millions of dollars. I’m sure there will be vendors willing to sell you this but I would pause before spending and think about all those large data lakes you were sold and how much ROI you actually got or think about those private cloud efforts or how much return you’re getting on a kubernetes cluster in a world of serverless? Caveat Emptor.
As a rule of thumb, if you’re not currently a hyperscaler then your platform engineering team should be spending most of its effort in getting rid of things from your organisation and building instrumentation for this.
WHAT COMES NEXT?
Oh, that’s where the fun really starts. If you look further up the map (figure 4) around the area of application and device this is where we get into the world of Spimes and SpimeScript. Though I suspect we’re going to call that CyberPhysical. Anyway, that’s another post for another year, we’re quite some way from that at the moment.
In the medium term, if figure 5 is correct, then we should be treated to a spectable in 2035 of a few enterprises announcing their adoption of cloud whilst many others announce their adoption of serverless just as the mainstream market finally admits that conversational programming (or whatever it will finally be called) is the norm. The difference between the “Haves” and the “Have Nots” in corporate technology will rarely have been starker.
SUMMARY
In summary, get yourself ready for a world of conversational programming. We’re not quite there yet but we should be there soon. When it arrives, embrace it and thank me later.
For interest, this is a wonderful article on Conversational Programming and GitHub’s CoPilot by Jess Martin.
IN THIS SERIES on “Why the fuss about conversational programming” …
[Jan 2023] What is conversational programming, PART I
[May 2023] Maps as code, PART II
[Nov 2023] Why open source AI matters, PART III
Originally published at https://blog.gardeviance.org.
