Why open source AI matters.
In the last post, I explored the idea of maps as code. In this post, we will dig a bit deeper and try to understand the essential role of open source in AI.
Before we start, let us acknowledge a few things.
It has been an exciting week for conversational programming with GPT-Builder, but let us also take a bow to the work of Aleksandar Simovic who pioneered many of these concepts in practice at RE:Invent 2018 combining an AI trained against AWS services, with an AI trained to develop and another AI converting voice to text. It’s always fun to watch the video.
Alex also presented at our study tour (back in the days when we used to run study tours) to a group of execs from many companies. I do hope they prepared for the changes. Before anyone goes off on a “who was first” tirade, Captain Janeway had you beat long ago.
Secondly, I know the prediction is a bit dated (see figure 1 below) but we’re not doing too bad. We’re still sorting out the winners and losers in the space at the moment (i.e. they haven’t yet clearly emerged) but it should become clear over the next few years. Amazon is entering the fray with Olympus. Oracle will probably announce it’ll win the space sometime around 2030, several years after the battle is over and everyone has gone home.
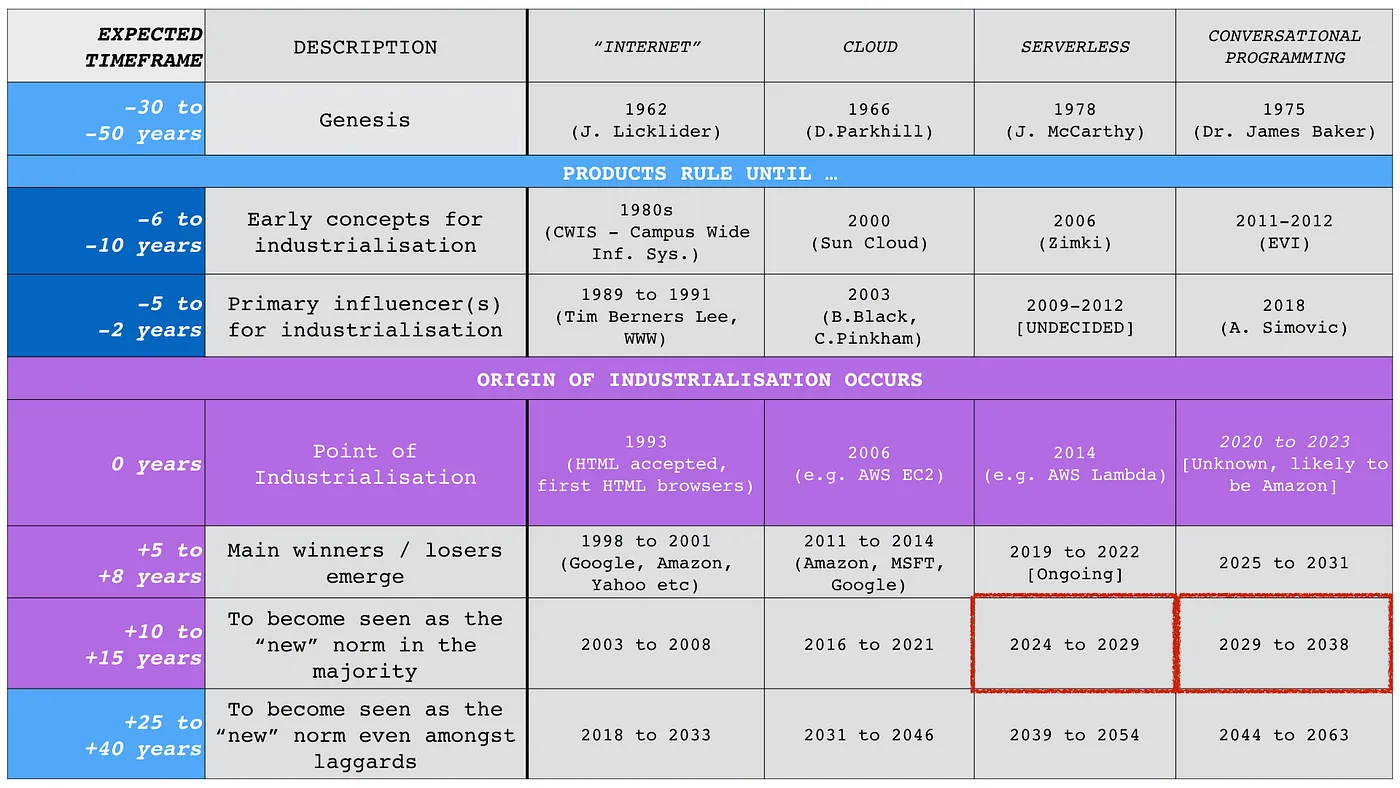
Thirdly, yes a lot of people in the mapping community have called out OpenAI on running an ILC like model. That is becoming clearer by the day, whether it is deliberate or not. Expect lots more harvesting of their ecosystem and the annual cry of “they’ve eaten my business model”.
What is code?
For our topic today, we need to understand what code is. Code is a set of symbolic instructions. They are symbols that alter the behaviour of the system. The following symbols …
#include <stdio.h>
int main() {
printf("Hello world");
return 0;
}… alter the system’s behaviour when they are executed, making it print the words “Hello world” to the screen. The executed bit is important, it needs a compiler to run. Without a compiler, those symbols are just text.
If you think about where we are heading with conversational programming, we are moving from a world where code is provided simply as text to a world where other forms of code can exist, such as maps. The reason for this is that it enables different forms of discussion to occur around the problem space. In the world of text, the conversation tends towards the rules, style and syntax i.e. does the text comply with the rules of the programming language? In the world of maps, the conversation tends towards objects, relationships and context.
A simple example is given in figure 2. What you have is the text (code) that creates a map. The conversation we have around the map is very different from the conversation we have around the text but then we’ve covered that in the previous post.

You’ve probably seen this difference in conversation for yourself. Walk into any engineering department, anywhere and you’ll find whiteboards. A very different conversation is happening on the whiteboard compared to what is happening when programming the text on a screen. Both conversations relate to the problem space. With earlier versions of ChatGPT (a LLM or large language model), I could provide the text (code) and discuss things such as syntax or whether it follows the rule (compilation errors etc). With ChatGPT4v (a LMM or large multi-modal model), I can provide the map itself and start a conversation about the map and its context.
The future of conversational programming is one where that visual conversation on the whiteboard is also part of the code, part of the symbolic instructions we use to program something. Code will become more than just text.
Code is more than text?
What might surprise you is that this has already happened.
In the past, data was operated on by code, but data didn’t change the behaviour of the system; it was separate. LLMs are systems which have been trained on data. That data consists of symbols and those symbols have changed the behaviour of the system (the model) through training. As a good friend of mine, Adam Bouhenguel, points out, the data is your code and the compiled version is your model weights.
With multi-modal systems (such as ChatGPT4v), the “model” can be trained with images, with sounds, and with a variety of other sources. It can be trained to recognise faces but what it recognises as a face will depend upon the images you provide. Maps are just images, and if ChatGPT4v wasn’t already programmed (i.e. trained) on images, then it wouldn’t be able to interpret, analyse and have a discussion with me around the map.
Our world is increasingly one where the symbolic instructions (the code) that change the system’s behaviour include text, data, images and many other things. Take the case of Aleksander above, he was programming with his voice in 2018 by having a conversation with the machine.
Text, data and images are not only part of the “source code” for the AIs in this world, they also will be used in prompts to create future software. For some AI, prompts will also be included in their training data. Prompts will also be “source code”.
Are today’s AIs open?
There is a danger here. Over many decades we have fought the open source battle to wrestle control from the hands of the few but we’ve been fixated with text. In our new world, the few have once again brought their proprietary ideas to the space but they’ve dressed themselves up as being open source because they open a subset of the symbolic instructions needed to create the system. I say subset because they don’t open, for example, training data which is also part of the symbolic instructions used to program the system.
Basic freedoms of open source include free redistribution, access to source code, freedom to modify, freedom to create derivative works and non-discrimination. Without ALL the symbolic instructions used to program the system, you can’t freely modify it. It’s not even open source when you hand me the model weights because that’s the compiled version. We need the actual source code (i.e. the training data used) and not some binary. Instead, even those who share model weights can often add clauses on its use. There is nothing remotely open about most of the AI projects out there claiming to be open.
To confuse things more, I hear the OSI is looking to redefine what open source means. Why? There is nothing wrong with what open source means. The problem is a whole bunch of people trying to claim that code (a set of symbolic instructions) doesn’t cover data or images (a set of symbolic instructions) and that somehow software (a collection of symbolic instructions) only includes the text bits of code. The OSI just needs to wake up and make it clear that this is not open source. All the symbolic instructions required to create the system need to be open for someone to call an AI open. We need all the source code, not just some of it.
Skynet is not the real danger of AI
We’re heading into a new era of high-level conversational programming, which is tied down with proprietary foundations dressed up as open. We are handing technological sovereignty (from individual to national) to a small group of players that we have no reason to suspect have your benevolence in mind.
Over the last decade, I have repeatedly warned that “the danger of machine intelligence isn’t malignant machines, it’s the use by people and concentration of power”. I have repeatedly warned about Feudal Lords. I have repeatedly warned why nurturing open source is so important, especially in multi-modal space. I’m tired of warnings; I need some sunshine.
Laughably, the UK led an AI safety summit last week. I say laugh, but if you’re in the UK then you might want to cry, especially given so many voices were ignored. You would have thought that handing over national sovereignty in the landscape of technology to a few would be THE major safety issue. Apparently not. The “great and good”, and lobbyists talking up “responsible AI” seemed focused on saving us from some future mythical frontier AI. I’m guessing they were all traumatised as younger children by James Cameron.
The real danger of AI comes not from mythical frontier AIs but from the concentration of power into a few, very human hands. From what I have been told, when it did get mentioned, it was mostly along the lines of the hazards of open source, guardrails and control, which is exactly where the lobbyists would take it. Be careful of groups promoting “responsible AI” when “responsible” is defined by that group, and you don’t get to look at what is happening behind closed doors out of concern for your “safety”. In the gloom, a ray of sunshine came in the form of Oliver Dowden who provides some backing to open source AI.
For a safe future of AI, look East.
There is one thing which we should all thank PM Rishi Sunak for. That was bringing China to the table and ignoring all the detractors. China is one of the countries which is not strategically inept. The summit was barely underway before China Gov signalled again its intended role in open source AI and a number of Chinese enterprises have reinforced that message since.
The UK would be wise to keep China close and follow them along an open path. I am assuming that we don’t want to sit and watch China accelerate, take over the AI space and have the benefits of AI shared amongst its population as we enter this new world of conversational programming.
If anyone is laughing, it has to be China. Before anyone says “whatabout” jobs or impact on creative rights or dangerous AIs, well those are important issues. Just remember, if the foundations are proprietary then you’ll have to accept whatever values others have coded into those foundations and since you can’t inspect them (as you don’t have access to most of the source code i.e. the training data) then you will have to rely on trying to test for anomolies. Yes, I know we have a nice new AI safety institute but we don’t stand a chance. What we need is all the source code and many eyeballs.
Where is our rebel alliance?
Hopefully, the EU under the AI act might create onerous and costly testing tasks for AI and add a tiered approach with a complete exemption for those AIs that are actually open and not just pretending to be. I know, it probably won’t, but maybe France and Mistral.ai could lead that charge? Even a nod towards exemptions of open source code would be good enough because the battle is one of “what do we mean by code”.
But I’m clutching at straws here. I was hoping the UK would lead the open charge. Instead, we are being led into gilded cages that are controlled for the benefit of a few … Where has our fight gone? Where is our rebel alliance? Where are the great and good of open source? Has everyone retired and is sitting too comfortably on a beach?
In the next post, I’ll cover what comes next. For that, we’re going to have to revisit the wonderful world of SpimeScript (or cyberphysical as some like to call it). It’ll make what is happening today look like the small potatoes it really is. Unfortunately, the dangers become even greater. Maybe this next time the UK could lead the way. We have enough time.
QUESTIONS
Q. If data is part of the code, what happens if you train your model on data that belongs to others?
A. Well, I would imagine that one set of lawyers are going to try and argue from a perspective of Bernstein v Skyviews — 1978 that there are limits to the “ordinary use and enjoyment” of your copyright and another set of lawyers are going to probably argue that your copyright extends to its use as code. Either way, it’s going to be an interesting case and there will be a lot of political pressure applied from both sides. If you want a better answer, I’d suggest talking to an IP lawyer because I’m not one of those. However, just so you know, all my mapping is creative commons share alike and has been for a very long time.
IN THIS SERIES on “Why the fuss about conversational programming” …
[Jan 2023] What is conversational programming, PART I
[May 2023] Maps as code, PART II
[Nov 2023] Why open source AI matters, PART III
Originally published at https://blog.gardeviance.org.
